A lot of hard work from Martin Michlmayr which provided quite an interesting reading.
A lot of hard work from Martin Michlmayr which provided quite an interesting reading.
XML + a XSLT toolchain is an excellent way to maintain your Curriculum Vitae, supporting several languages and several formats with minimum effort. I've been using the XML Résumé Library for my CV for a while, but the lack of recent updates and a slight unsatisfaction with the look of the PDF output made me want to take a peek on what else is out there.
Didn't find much though: the overall feeling I get is that, though not perfect, the XML Résumé Library seems to be the safest bet out there.
The sole exception worth mention is the work done by David Sora for a subject of his masters degree. He designed a XSD schema together with HTML and PDF XSLT stylesheets for CVs based upon the Europass Curriculum Vitae layout. His report is written in portuguese, but an example CV and XSLT are available for english too (in the parent directory of the report). This might not be picked up a community (such as the one behind XML Résumé Library), but the schema is complete and the output looks nice. Also the layout of the Europass CV is comprehensive and professional — as you'd expect from an initiative backed by the European Union. So definitelyinetly something to look upon whenever I need to tweak or drop the XML Résumé Library.
Technorati Tags: xml, xslt, cvudev has replaced hotplug in the Debian distribution. However not all hotplug's functionality is available (or at least simple to use): with hotplug one could easily write scripts which processed add and remove events, while with udev that has proved to be quite an ordeal.
The device I wanted to detect was the SpeedTouch USB ADSL modem. The first problem I ran into was that "sysfs values are not readable at remove, because the device directory is already gone". The solution is either using an environment variable with the DEVPATH (which didn't work for me), or matching the device with the reduced information available (my only remaining option). Thankfully there was this PRODUCT environment variable which could precisely match the device. This is how the udev rules look:
# /etc/udev/rules.d/z80_speedtch.rules
BUS=="usb", SUBSYSTEM=="usb", SYSFS{idVendor}=="06b9", SYSFS{idProduct}=="4061", ACTION=="add", RUN+="/bin/sh -c '/usr/local/sbin/speedtouch &'"
BUS=="usb", SUBSYSTEM=="usb", ENV{PRODUCT}=="6b9/4061/0", ACTION=="remove", RUN+="/bin/sh -c '/usr/local/sbin/speedtouch &'"
The actions I wanted to take was to start/stop the ppp interface. The second problem is that the above rules matched many add/remove events (driver, and several USB subdevices). To ensure only one add/remove action is taken, a solution is to use the SEQNUM environment variable, whose value is a always increasing integer, and keep track of its value when the device first got inserted. This is how /usr/local/sbin/speedtouch looks like:
#!/bin/sh
RUN=/var/run/speedtouch.seqnum
TIMEOUT=60
# test whether the device is currently added or not
device_added () {
test -e $RUN && test `cat $RUN` -lt $SEQNUM
}
# wait for the "ADSL line is up" kernel message to appear
wait_for_adsl_up () {
local TIME
dmesg -c > /dev/null
TIME=0
while ! dmesg | grep -q 'ADSL line is up'
do
sleep 1
TIME=$(($TIME+1))
test $TIME -ge $TIMEOUT && return 1
done
}
case $ACTION in
add)
# ignore repeated "add" actions
device_added && exit
echo $SEQNUM > $RUN
wait_for_adsl_up
ifup ppp0
;;
remove)
# ignore repeated "remove" actions
device_added || exit
rm -f $RUN
ifdown ppp0
;;
esac
The script has a bit more magic for waiting for the ADSL line is up, which was taken from the SpeedTouch Linux kernel driver homepage.
Technorati Tags: linux, debian, shell scriptsHave you ever did mental math to figure out how to best fit a collection of data into a set of DVDs, trying to squeeze the most into every single DVD? It happens more and more to me, so I wrote a Python script to do it for me.
The algorithm used to efficiently find the largest path combinations below a threshold is inspired in the apriori algorithm for association rule discovery. Since the largest path combination is a superset of smaller combinations, we can start building those starting from single paths, combine those with the initial to make two-item sets while removing all larger than the threshold, then three-item, four-item, and so on; until no larger combination below the threshold can be found.
Here is the script:
#!/usr/bin/env python
# mixnmatch.py - find combination of files/dirs that sum below a given threshold
# -- Jose Fonseca
import os
import os.path
import optparse
import sys
from sets import ImmutableSet as set
def get_size(path):
if os.path.isdir(path):
result = 0
for name in os.listdir(path):
result += get_size(os.path.join(path, name))
return result
else:
return os.path.getsize(path)
def mix_and_match(limit, items, verbose = False):
# filter items
items = [(size, name) for size, name in items if size <= limit]
# sort them by size
items.sort(lambda (xsize, xname), (ysize, yname): cmp(xsize, ysize))
# initialize variables
added_collections = dict([(set([name]), size) for size, name in items])
collections = added_collections
while True:
if verbose:
sys.stderr.write("%d\n" % len(collections))
# find unique combinations of the recent collections
new_collections = {}
for names1, size1 in added_collections.iteritems():
for size2, name2 in items:
size3 = size1 + size2
if size3 > limit:
# we can break here as all collections that follow are
# bigger in size due to the sorting above
break
if name2 in names1:
continue
names3 = names1.union(set([name2]))
if names3 in new_collections:
continue
new_collections[names3] = size3
if len(new_collections) == 0:
break
collections.update(new_collections)
added_collections = new_collections
return [(size, names) for names, size in collections.iteritems()]
def main():
parser = optparse.OptionParser(usage="\n\t%prog [options] path ...")
parser.add_option(
'-l', '--limit',
type="int", dest="limit", default=4700000000,
help="total size limit")
parser.add_option(
'-s', '--show',
type="int", dest="show", default=10,
help="number of combinations to show")
parser.add_option(
'-v', '--verbose',
action="store_true", dest="verbose", default=False,
help="verbose output")
(options, args) = parser.parse_args(sys.argv[1:])
limit = options.limit
items = [(get_size(arg), arg) for arg in args]
collections = mix_and_match(limit, items, options.verbose)
collections.sort(lambda (xsize, xnames), (ysize, ynames): -cmp(xsize, ysize))
if options.show != 0:
collections = collections[0:options.show]
for size, names in collections:
percentage = 100.0*float(size)/float(limit)
try:
sys.stdout.write("%10d\t%02.2f%%\t%s\n" % (size, percentage, " ".join(names)))
except IOError:
# ignore broken pipe
pass
if __name__ == '__main__':
main()
This script has also been posted as a Python Cookbook Recipe.
I upgraded my broadband connection to one where there is no traffic limit during the night (appropriately referred by my ISP as "happy hours"!). I was already using rrdtool to monitor the total incoming traffic of my router, but now I wanted to separate the traffic according to a schedule.
It was obvious that at least two data sources are needed: one for the normal (limited) traffic and another for the happy (unlimited) traffic. The first (naive) approach was to create these two data sources plus an automatically computed total data source, as
rrdtool create $RRD \ -s $STEP \ DS:normal:COUNTER:$HEARTBEAT:$MIN:$MAX \ DS:happy:COUNTER:$HEARTBEAT:$MIN:$MAX \ DS:total:COMPUTE:normal,happy,+ \ RRA:AVERAGE:$XFF:$(($STEP/$STEP)):$((2*$DAY/$STEP)) \ RRA:AVERAGE:$XFF:$(($HOUR/$STEP)):$((2*$MONTH/$HOUR)) \ RRA:AVERAGE:$XFF:$(($DAY/$STEP)):$((2*$YEAR/$DAY))
and feed either according to the current time of the day:
TIME=N
COUNTER=`snmpget ...`
TIMEOFDAY=`date +'%H%M'`
if [ $TIMEOFDAY -gt $HAPPYSTART -a $TIMEOFDAY -le $HAPPYEND ]
then
NORMAL=0
HAPPY=$COUNTER
else
NORMAL=$COUNTER
HAPPY=0
fi
rrdtool update $RRD $TIME:$NORMAL:$HAPPY
where HAPPYSTART and TIMEOFDAY have the happy hour start and end times in hhmm format.
However this does not work as expected due to the way rrdtool treats the COUNTER data sources, and the impact of the schedule transition on such treatment. For illustration purposes, suppose in one instant t1 the counter value is 1000 bytes and in the normal schedule, and the next instant t2 the counter value is 1001 bytes but on the happy schedule. The updates will be
t1:1000:0 t2:0:1001
but rrdtool will see and count the happy counter vary from 0 to 1001, therefore counting 1001 bytes, and not the correct value of 1 byte!
The solution is have only one COUNTER, and separate the traffic kind using a factor in the [0, 1] range as:
rrdtool create $RRD \ -s $STEP \ DS:total:COUNTER:$HEARTBEAT:$MIN:$MAX \ DS:ratio:GAUGE:$HEARTBEAT:0:1 \ DS:normal:COMPUTE:total,ratio,* \ DS:happy:COMPUTE:total,1,ratio,-,* \ RRA:AVERAGE:$XFF:$(($STEP/$STEP)):$((2*$DAY/$STEP)) \ RRA:AVERAGE:$XFF:$(($HOUR/$STEP)):$((2*$MONTH/$HOUR)) \ RRA:AVERAGE:$XFF:$(($DAY/$STEP)):$((2*$YEAR/$DAY))
and for the update:
TIME=N
COUNTER=`snmpget ...`
TIMEOFDAY=`date +'%H%M'`
if [ $TIMEOFDAY -gt $HAPPYSTART -a $TIMEOFDAY -le $HAPPYEND ]
then
RATIO=0
else
RATIO=1
fi
rrdtool update $RRD $TIME:$COUNTER:$RATIO
With this I get nice pictures such as this one:
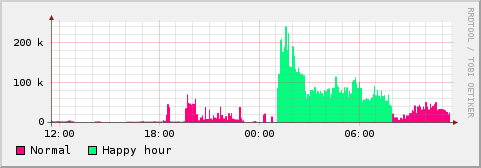
So I've finally created a blog...
I'm not sure yet what sort of stuff I want to write about (Nem tenho a certeza que língua usar!) but I hope the answer eventually comes to me and that this blog becomes something useful to me or others.
At the very least I've got a hold of the blogspot address with my name! :)