We found that for many applications a substantial part of the time spent in software vertex processing was being spend in the powf function. So quite a few of us in Tungsten Graphics have been looking into a faster powf.
Introduction
The basic way to compute powf(x, y) efficiently is by computing the equivalent exp2(log2(x)*y)) expression, and then fiddle with IEEE 754 floating point exponent to quickly estimate the log2/exp2. This by itself only gives a very coarse approximation. To improve this approximation one has to also look into the mantissa, and then take one of two alternatives: use a lookup table or fit a function like a polynomial.
Lookup table
See also:
exp2
union f4 {
int32_t i[4];
uint32_t u[4];
float f[4];
__m128 m;
__m128i mi;
};
#define EXP2_TABLE_SIZE_LOG2 9
#define EXP2_TABLE_SIZE (1 << EXP2_TABLE_SIZE_LOG2)
#define EXP2_TABLE_OFFSET (EXP2_TABLE_SIZE/2)
#define EXP2_TABLE_SCALE ((float) ((EXP2_TABLE_SIZE/2)-1))
/* 2 ^ x, for x in [-1.0, 1.0[ */
static float exp2_table[2*EXP2_TABLE_SIZE];
void exp2_init(void)
{
int i;
for (i = 0; i < EXP2_TABLE_SIZE; i++)
exp2_table[i] = (float) pow(2.0, (i - EXP2_TABLE_OFFSET) / EXP2_TABLE_SCALE);
}
/**
* Fast approximation to exp2(x).
* Let ipart = int(x)
* Let fpart = x - ipart;
* So, exp2(x) = exp2(ipart) * exp2(fpart)
* Compute exp2(ipart) with i << ipart
* Compute exp2(fpart) with lookup table.
*/
__m128
exp2f4(__m128 x)
{
__m128i ipart;
__m128 fpart, expipart;
union f4 index, expfpart;
x = _mm_min_ps(x, _mm_set1_ps( 129.00000f));
x = _mm_max_ps(x, _mm_set1_ps(-126.99999f));
/* ipart = int(x) */
ipart = _mm_cvtps_epi32(x);
/* fpart = x - ipart */
fpart = _mm_sub_ps(x, _mm_cvtepi32_ps(ipart));
/* expipart = (float) (1 << ipart) */
expipart = _mm_castsi128_ps(_mm_slli_epi32(_mm_add_epi32(ipart, _mm_set1_epi32(127)), 23));
/* index = EXP2_TABLE_OFFSET + (int)(fpart * EXP2_TABLE_SCALE) */
index.mi = _mm_add_epi32(_mm_cvtps_epi32(_mm_mul_ps(fpart, _mm_set1_ps(EXP2_TABLE_SCALE))), _mm_set1_epi32(EXP2_TABLE_OFFSET));
expfpart.f[0] = exp2_table[index.u[0]];
expfpart.f[1] = exp2_table[index.u[1]];
expfpart.f[2] = exp2_table[index.u[2]];
expfpart.f[3] = exp2_table[index.u[3]];
return _mm_mul_ps(expipart, expfpart.m);
}
log2
#define LOG2_TABLE_SIZE_LOG2 8
#define LOG2_TABLE_SIZE (1 << LOG2_TABLE_SIZE_LOG2)
#define LOG2_TABLE_SCALE ((float) ((LOG2_TABLE_SIZE)-1))
/* log2(x), for x in [1.0, 2.0[ */
static float log2_table[2*LOG2_TABLE_SIZE];
void log2_init(void)
{
unsigned i;
for (i = 0; i < LOG2_TABLE_SIZE; i++)
log2_table[i] = (float) log2(1.0 + i * (1.0 / (LOG2_TABLE_SIZE-1)));
}
__m128
log2f4(__m128 x)
{
union f4 index, p;
__m128i exp = _mm_set1_epi32(0x7F800000);
__m128i mant = _mm_set1_epi32(0x007FFFFF);
__m128i i = _mm_castps_si128(x);
__m128 e = _mm_cvtepi32_ps(_mm_sub_epi32(_mm_srli_epi32(_mm_and_si128(i, exp), 23), _mm_set1_epi32(127)));
index.mi = _mm_srli_epi32(_mm_and_si128(i, mant), 23 - LOG2_TABLE_SIZE_LOG2);
p.f[0] = log2_table[index.u[0]];
p.f[1] = log2_table[index.u[1]];
p.f[2] = log2_table[index.u[2]];
p.f[3] = log2_table[index.u[3]];
return _mm_add_ps(p.m, e);
}
pow
static inline __m128
powf4(__m128 x, __m128 y)
{
return exp2f4(_mm_mul_ps(log2f4(x), y));
}
Polynomial
For more details see:
exp2
#define EXP_POLY_DEGREE 3
#define POLY0(x, c0) _mm_set1_ps(c0)
#define POLY1(x, c0, c1) _mm_add_ps(_mm_mul_ps(POLY0(x, c1), x), _mm_set1_ps(c0))
#define POLY2(x, c0, c1, c2) _mm_add_ps(_mm_mul_ps(POLY1(x, c1, c2), x), _mm_set1_ps(c0))
#define POLY3(x, c0, c1, c2, c3) _mm_add_ps(_mm_mul_ps(POLY2(x, c1, c2, c3), x), _mm_set1_ps(c0))
#define POLY4(x, c0, c1, c2, c3, c4) _mm_add_ps(_mm_mul_ps(POLY3(x, c1, c2, c3, c4), x), _mm_set1_ps(c0))
#define POLY5(x, c0, c1, c2, c3, c4, c5) _mm_add_ps(_mm_mul_ps(POLY4(x, c1, c2, c3, c4, c5), x), _mm_set1_ps(c0))
__m128 exp2f4(__m128 x)
{
__m128i ipart;
__m128 fpart, expipart, expfpart;
x = _mm_min_ps(x, _mm_set1_ps( 129.00000f));
x = _mm_max_ps(x, _mm_set1_ps(-126.99999f));
/* ipart = int(x - 0.5) */
ipart = _mm_cvtps_epi32(_mm_sub_ps(x, _mm_set1_ps(0.5f)));
/* fpart = x - ipart */
fpart = _mm_sub_ps(x, _mm_cvtepi32_ps(ipart));
/* expipart = (float) (1 << ipart) */
expipart = _mm_castsi128_ps(_mm_slli_epi32(_mm_add_epi32(ipart, _mm_set1_epi32(127)), 23));
/* minimax polynomial fit of 2**x, in range [-0.5, 0.5[ */
#if EXP_POLY_DEGREE == 5
expfpart = POLY5(fpart, 9.9999994e-1f, 6.9315308e-1f, 2.4015361e-1f, 5.5826318e-2f, 8.9893397e-3f, 1.8775767e-3f);
#elif EXP_POLY_DEGREE == 4
expfpart = POLY4(fpart, 1.0000026f, 6.9300383e-1f, 2.4144275e-1f, 5.2011464e-2f, 1.3534167e-2f);
#elif EXP_POLY_DEGREE == 3
expfpart = POLY3(fpart, 9.9992520e-1f, 6.9583356e-1f, 2.2606716e-1f, 7.8024521e-2f);
#elif EXP_POLY_DEGREE == 2
expfpart = POLY2(fpart, 1.0017247f, 6.5763628e-1f, 3.3718944e-1f);
#else
#error
#endif
return _mm_mul_ps(expipart, expfpart);
}
log2
#define LOG_POLY_DEGREE 5
__m128 log2f4(__m128 x)
{
__m128i exp = _mm_set1_epi32(0x7F800000);
__m128i mant = _mm_set1_epi32(0x007FFFFF);
__m128 one = _mm_set1_ps( 1.0f);
__m128i i = _mm_castps_si128(x);
__m128 e = _mm_cvtepi32_ps(_mm_sub_epi32(_mm_srli_epi32(_mm_and_si128(i, exp), 23), _mm_set1_epi32(127)));
__m128 m = _mm_or_ps(_mm_castsi128_ps(_mm_and_si128(i, mant)), one);
__m128 p;
/* Minimax polynomial fit of log2(x)/(x - 1), for x in range [1, 2[ */
#if LOG_POLY_DEGREE == 6
p = POLY5( m, 3.1157899f, -3.3241990f, 2.5988452f, -1.2315303f, 3.1821337e-1f, -3.4436006e-2f);
#elif LOG_POLY_DEGREE == 5
p = POLY4(m, 2.8882704548164776201f, -2.52074962577807006663f, 1.48116647521213171641f, -0.465725644288844778798f, 0.0596515482674574969533f);
#elif LOG_POLY_DEGREE == 4
p = POLY3(m, 2.61761038894603480148f, -1.75647175389045657003f, 0.688243882994381274313f, -0.107254423828329604454f);
#elif LOG_POLY_DEGREE == 3
p = POLY2(m, 2.28330284476918490682f, -1.04913055217340124191f, 0.204446009836232697516f);
#else
#error
#endif
/* This effectively increases the polynomial degree by one, but ensures that log2(1) == 0*/
p = _mm_mul_ps(p, _mm_sub_ps(m, one));
return _mm_add_ps(p, e);
}
Results
The accuracy vs speed for several table sizes and
polynomial degrees can be seen in the chart below.
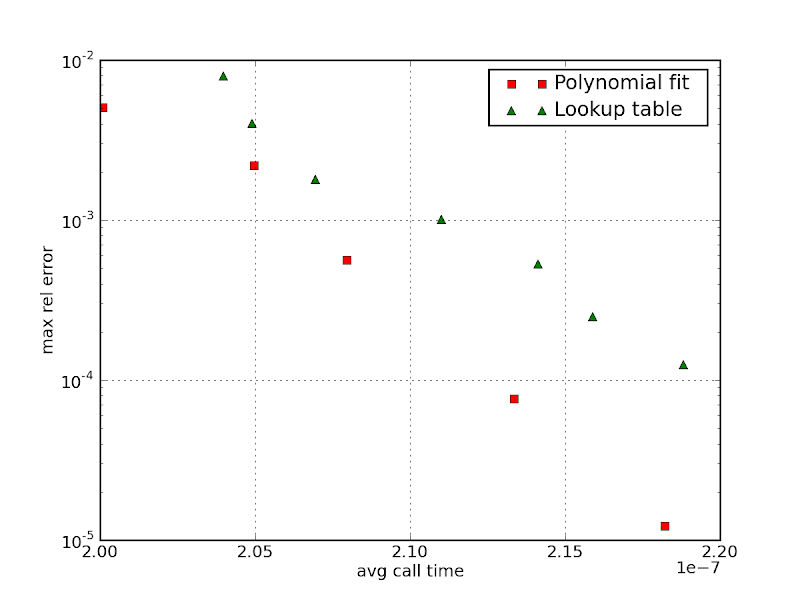
The difference is not much, but the polynomial approach outperforms
the table approach for any desired precision. This was for 32bit
generated code in a Core 2. If generating 64bit code, the difference
between the two is bigger. The performance of the table approach will
also tend to degrade when other computation is going on at the same
time, as the likelihood the lookup tables get trashed out of the cache
is higher. So by all accounts, the polynomial approach seems a safer
bet.






